LevelDB源码解析(9) FilterBlockBuilder
背景
Filter block为SST中一个区块,filter block由多个filter组成,每个data block对应一个filter(但是一个filter可能对应多个data block)。LevelDB在进入data block中查找前会先检查filter,如果filter判断key不在,那么key一定不在这个block中,就不用进入data block查找了,filter判断key可能存在才会进入data block查找。
Filter block由FilterBlockBuilder负责构建,下面我们先看一下FilterBlockBuilder的结构和成员函数。最后举个例子详细解释创建filter的完整过程,以方便理解。
FilterBlockBuilder类定义
//源码文件:table/filter_block.h
class FilterBlockBuilder {
public:
explicit FilterBlockBuilder(const FilterPolicy*);
void StartBlock(uint64_t block_offset);
void AddKey(const Slice& key);
Slice Finish();
private:
void GenerateFilter();
const FilterPolicy* policy_; //filter policy,比如BloomFilter
std::string keys_; //key 列表
std::vector<size_t> start_; //key位置列表
std::string result_; //filter列表的buffer
std::vector<Slice> tmp_keys_; //临时存储已插入的key
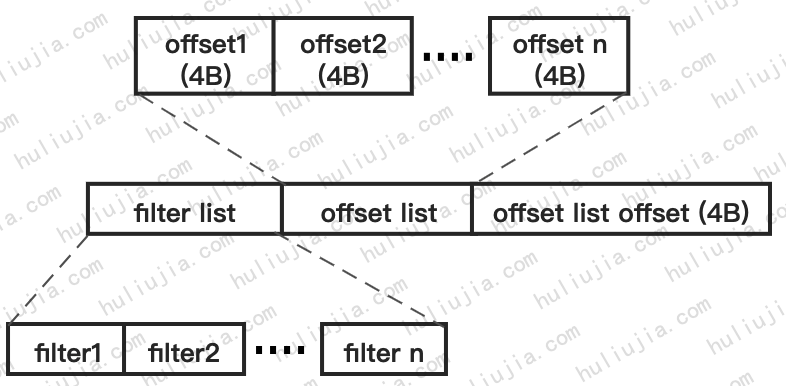
std::vector<uint32_t> filter_offsets_; //filter的offset
};
FilterBlockBuilder::AddKey
//源码文件:table/filter_block.cc
void FilterBlockBuilder::AddKey(const Slice& key)
{
Slice k = key;
start_.push_back(keys_.size());
keys_.append(k.data(), k.size());
}
keys_是一个string类型,所有key都顺序存放在keys_中,start_是一个数组,保存了每个key在keys_中的offset。start_[i]表示第i个key的offset。
AddKey把key保存到key列表中。
FilterBlockBuilder::StartBlock
StartBlock的任务是根据block_offset创建filter,filter的数量和block的数量无关,只和block_offset有关。默认每2K block_offset就创建一个filter。默认值2K是由常量kFilterBase指定的。
//源码文件:table/filter_block.cc
void FilterBlockBuilder::StartBlock(uint64_t block_offset)
{
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while ( filter_index > filter_offsets_.size())
{
GenerateFilter();
}
}
所有filter顺序存储在result_中的,filter_offsets_[i]表示第i个filter在result_中的offset。每个data block写入文件后,都会调用StartBlock,多个data block也是顺序存储的,传入的block_offset并不是这次的data block自己的offset,而是这次data block的offset + size,也就是下一个data block的offset,也等于当前写入的所有data block的总size。
filter_index = block_offset / 2K 计算需要的filter数量,filter_offsets_的size就是filter的数量。比如block_offset是5K,那么filter_index就等于2,需要两个filter。如果下次调用的block_offset是5.5K,那么计算出来的filter_index还是2,不会新建filter。查找时使用block的offset除以2K得到filter在filter_offsets_中的位置,然后根据filter offset找到filter。
FilterBlockBuilder::GenerateFilter
GenerateFilter用keys_和start_中保存的key列表创建一个filter,创建完成后清空keys_和start_。
//源码文件:table/filter_block.cc
void FilterBlockBuilder::GenerateFilter()
{
const size_t num_keys = start_.size();
//Step1
if ( num_keys == 0 )
{
filter_offsets_.push_back(result_.size());
return;
}
//Step2
start_.push_back(keys_.size());
tmp_keys_.resize(num_keys);
for ( size_t i = 0; i < num_keys; i++ )
{
const char *base = keys_.data() + start_[i];
size_t length = start_[i + 1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
//Step3
filter_offsets_.push_back(result_.size());
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
//Step4
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
Step1:如果key数量为0,把下一个filter的offset放入filter_offsets_中,即让filter offset指向下一个filter。
Step2:把keys_中的key解析出来放到tmp_keys_中。
Step3:调用CreateFilter创建filter,新建的filter会被append到result_中。policy_是一个抽象类指针,默认用的policy是BloomFilter。
Step4:重置Builder的数据,为下一个filter做准备。
FilterBlockBuilder::Finish
Slice FilterBlockBuilder::Finish()
{
if ( !start_.empty())
{
GenerateFilter();
}
const uint32_t array_offset = result_.size();
for ( size_t i = 0; i < filter_offsets_.size(); i++ )
{
PutFixed32(&result_, filter_offsets_[i]);
}
PutFixed32(&result_, array_offset);
result_.push_back(kFilterBaseLg);
return Slice(result_);
}
调用Finish完成filter block的构建,Finish会先为剩余的key创建一个新的filter,然后把filter offset列表按照顺序编码到result_中,把offset列表的offset编码到result_最后面。最后把常量kFilterBaseLg添加到最后,默认为11,2^11=2048=2KB,是为了表明每多少block_offset创建一个filter。
filter block的结构
最终filter block的结构如下图所示:
举个栗子
创建filter这里的逻辑挺绕的,为了方便理解,这里举个栗子吧。
假设我们总共创建了5个data block,size分别为1K、3K、10K、0.5K、0.3K、2K,总size为16.8K。
下面我们分别理一下每个block写完后调用StartBlock的计算过程:
- block1调用,block_offset为1K,1K/2K=0,0-0=0。所以不会新增filter offset。
- block2调用,block_offset为4K,4K/2K=2,2-0=0。所以新增两个filter offset,为第一个filter offset调用GenerateFilter时,因为key数量大于0,所以会创建一个filter,就叫Filter1吧。filter_offsets_[0]指向Filter1。但是为第二个filter offset调用GenerateFilter时,因为keys已经被清空了,所以这里不会创建filter,而是让filter_offsets_[1]指向Filter2(Filter2此时还不存在,其实是指向了result_的尾部)。
- block3调用,block_offset为14K,14K/2K=7,7-2=5。所以新增5个filter offset。类似的,只有新增第一个filter offset时才会创建filter(Filter2),并让filter_offsets_[2]指向Filter2。类似的,剩下的4个filter offset(3,4,5,6)因为keys已经被清空了,所以都指向了Filter3。
- block4调用,block_offset为14.5K,14.5K/2K=7,7-7=0。所以do nothing。
- block5调用,block_offset为14.8K,14.8K/2K=7,7-7=0。所以也不会新增filter offset。
- block6调用,block_offset为16.8K,16.8K/2K=8,8-7=1。所以新增一个filter offset,并且会创建filter(Filter3),filter_offsets_[7]指向Filter3。
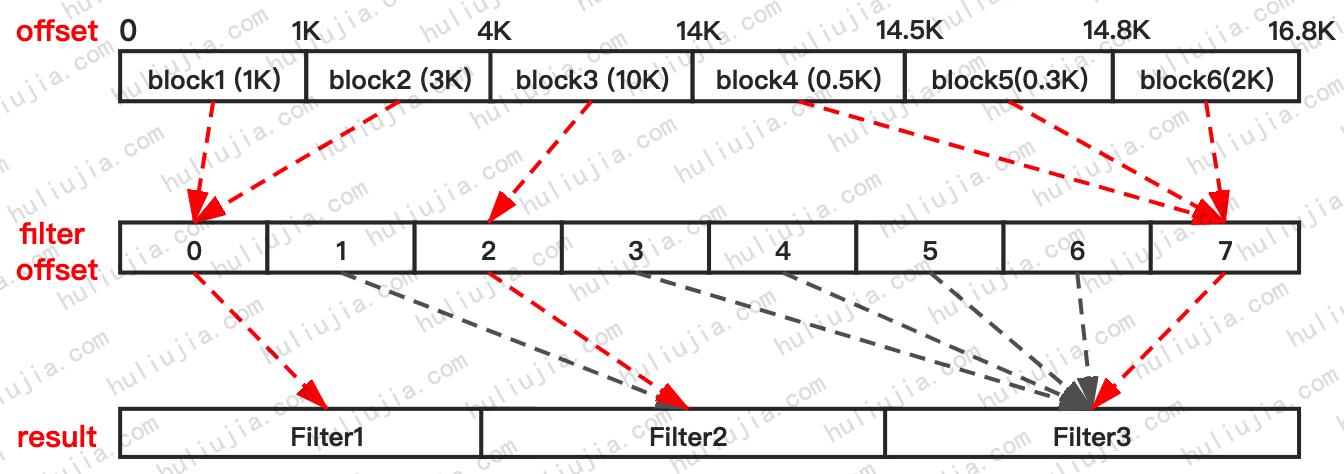
最终总共产生了8个filter offset和8个filter,其中block1和block2共用Filter1,block3独占Filter2,block4、block5、block6共用Filter3。
可以看到其实filter_offsets_[1,3,4,5,6]不对应任何data block,仅仅是占位用的。每个block根据自己的offset(注意,这里的offset指block的首地址,有别于调用StartBlock时传入的block_offset)除以2K就是对应的filter_offset。有效的对应关系在图中均以红色虚线表示,灰色虚线表示无效的对应关系。
源码版本
- 原文作者:胡刘郏
- 原文链接:https://www.huliujia.com/blog/1a8dbd0991/