LevelDB源码解析(11) SST文件结构
背景
前面我们逐渐深入的介绍了LevelDB从插入key-value到落盘的整个过程,感兴趣的读者可以移步相关文章:
- LevelDB源码解析(4) MemTable
- LevelDB源码解析(5) WriteBatch
- LevelDB源码解析(6) 写任务(WriterBatch)合并
- LevelDB源码解析(7) 预写日志(WAL)
- LevelDB源码解析(8) BlockBuilder
- LevelDB源码解析(9) FilterBlockBuilder
- LevelDB源码解析(10) TableBuilder(Memtable序列化)
涉及到SST文件结构的内容都比较分散,这里做一个集中的梳理。
SST整体结构
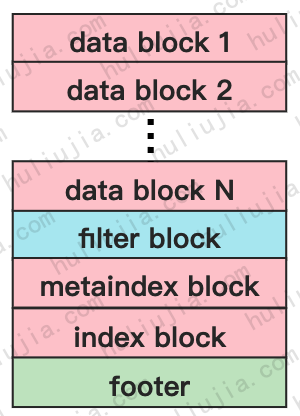
整个SST文件由N个data block,1个filter block,1个metaindex block,1个index block和1个footer组成。
其中data block、filter block、metaindex block复用了相同的存储结构,为了方便描述,这里我们称之为X block吧。
下面我们分别介绍X block、filter blcok和footer的结构。
X block
X block由BlockBuilder完成构建,结构如下图所示:
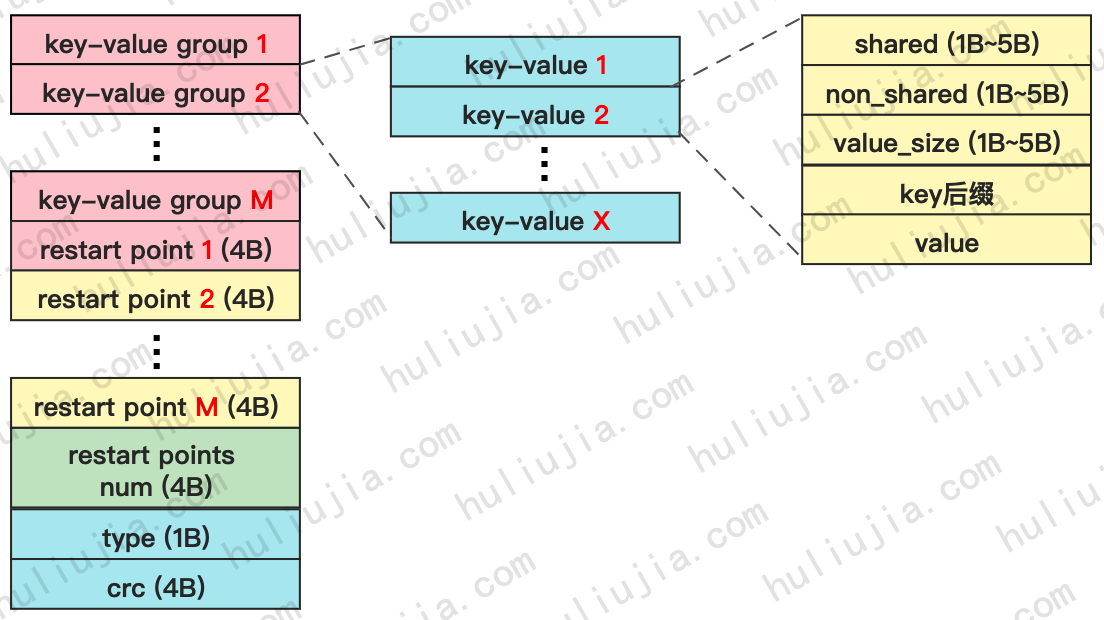
其中restart point和key-value group是一一对应的,restart point i 表示第 i 个key-value group在SST文件中的offset。
一个 key-value group 包含X个key-value。
对于data block来说,X默认为16,即每16个key为一组进行前缀合并。
对于index block来说,X默认为1,即每个key-value group只有一个key-value,restart point还是存在的,只是没有意义,因为不存在复用key前缀的情况。index block中每个key-value表示一个index entry,指向一个data block。其中,key为这个data block的最大key(或者最短的比data block最大key大的key),value为8个字节,存储了data block的在SST文件中的offset和size。
对于metaindex block来说,整个block只有一个key-value,key为filter block的name,value为filtr block的offset和size。
每个key-value的存储分为5个部分,如上图最右侧所示。一个key-value group中,除了第一个key必须存储完整key,其他key如果和第一个key有共同前缀,都只存key后缀。
shared、non_shared分别表示共同前缀和key后缀的长度,value_size表示value的size。这三个值都是使用变长编码来存储的,所以占用的空间从1字节到5字节不等。
type字段只有两种值,用于表示当前block的数据是否压缩过。type=0,表示没有压缩,type=1表示压缩了,如果压缩了,那么type之前的数据存储的是压缩格式,解压后才是上图所示的格式。
crc是基于block的数据计算出来的校验和,用于校验block的数据是否损坏。
Filter Block
Filter block由FilterBlockBuilder完成构建,结构如下图右侧所示:
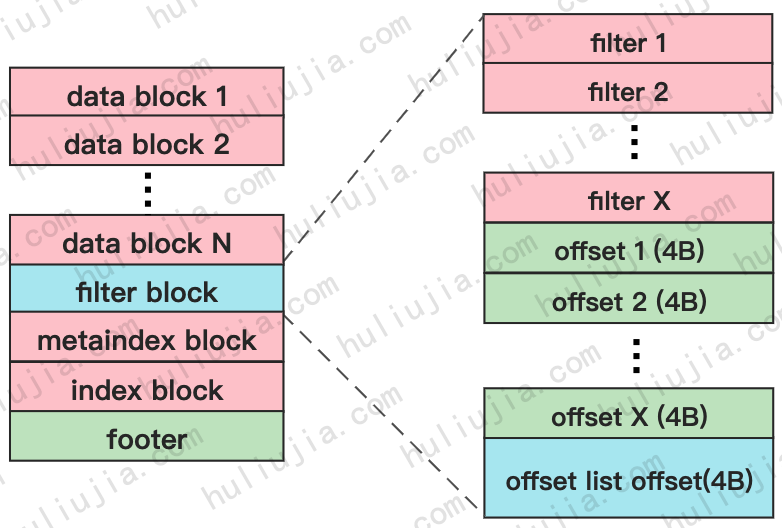
filter和data block不是一一对应的,一个filter block可能同时对应多个data block,即这几个data blcok的数据都在这个filter里。但是一个data block会且只会对应一个data block。所以filter的数量一定小于等于data block的数量。
offset i 存放的是第 i 个filter在SST文件中的offset。而offset list offset存放的是offset list在SST文件中的offset。
Footer 结构
TableBuilder完成前面全部block的构建后,就会创建footer,footer的结构如下图右侧所示:
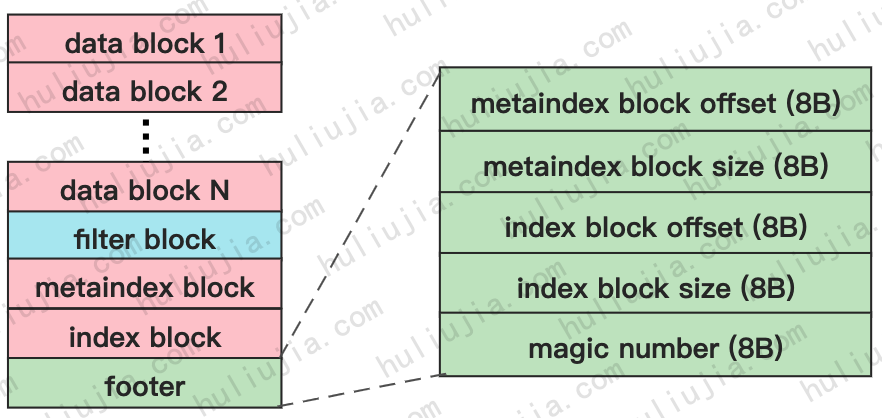
源码版本
- 原文作者:胡刘郏
- 原文链接:https://www.huliujia.com/blog/6974db6de9/